
C言語では、異なる型のデータを一つにまとめて新しいデータ型を作るための構造体と共用体という機能が提供されています。この章では、構造体と共用体について詳しく説明します。
構造体
構造体は、異なる型の複数のデータを一つに束ねるデータ構造です。簡単に言うと、「カスタムデータ型」のことです。データ構造を定義するには、「struct」キーワードが使われます。
以下に構造体を使用する手順を説明します。
1.構造体の定義
構造体は以下のように定義します。
struct 構造体名{
型1 変数名1;
型2 変数名2;
;
};structを記述し、{}で囲んだ中にメンバ変数とその型を宣言します。
これらの変数をメンバと呼びます。型はメンバごとに異なっても同じでもかまいません。また、メンバとして配列を宣言することもできます。
末尾に;(セミコロン)を付けます。
2.構造体の宣言
定義した構造体を使うため、構造体型の変数を宣言します。
struct 構造体名 変数名;構造体の変数を宣言しメモリ上に領域を確保します。
3.構造体型の変数の初期化
他の変数と同様に、構造体型の変数を初期化をすることができます。
struct 構造体名 変数名={値1,値2,,,};
{}の中にカンマで区切り値を列挙します。
4.構造体のメンバへのアクセス
構造体のメンバへのアクセスは以下のように記述します。
変数名.メンバ名;変数名の次にドット演算子(.)を記述することで、構造体の各メンバへアクセスすることができます。
では、実際に構造体を定義し、構造体の各メンバの値に参照するサンプルプログラムを書いてみます。このサンプルでは、生徒の名前、年齢、身長、体重の情報をひとまとめにして構造体として定義しています。
#include <stdio.h>
struct student{
char name[20];
int age;
double height;
double weight;
};
int main(void){
struct student v1={"Yamada Taro",20,179.5,70.5};
printf("名前=%s\n",v1.name);
printf("年齢=%d歳\n",v1.age);
printf("身長=%fcm\n",v1.height);
printf("体重=%fkg\n",v1.weight);
return 0;
}実行結果
名前=Yamada Taro
年齢=20歳
身長=179.500000cm
体重=70.500000kg
また、構造体を配列として扱うこともできます。
#include <stdio.h>
struct student{
char name[20];
int age;
double height;
double weight;
};
int main(void){
struct student v1[5]={
{"Yamada Taro",20,180.5,75.0},
{"Suzuki Ichiro",21,170.5,65.0},
{"Yamada Hanako",22,160.5,55.0},
{"Sato Jiro",18,175.5,68.0},
{"Hayashi saburo",19,178.5,68.3}
};
int count;
count = sizeof(v1) / sizeof(struct student) ;
for(int i=0;i<count;i++){
printf("名前=%s\n",v1[i].name);
printf("年齢=%d歳\n",v1[i].age);
printf("身長=%fcm\n",v1[i].height);
printf("体重=%fkg\n",v1[i].weight);
printf("*********\n");
}
return 0;
}count = sizeof(v1) / sizeof(struct student) は構造体配列の要素数を計算しています。
実行結果
名前=Yamada Taro
年齢=20歳
身長=180.500000cm
体重=75.000000kg
*********
名前=Suzuki Ichiro
年齢=21歳
身長=170.500000cm
体重=65.000000kg
*********
名前=Yamada Hanako
年齢=22歳
身長=160.500000cm
体重=55.000000kg
*********
名前=Sato Jiro
年齢=18歳
身長=175.500000cm
体重=68.000000kg
*********
名前=Hayashi saburo
年齢=19歳
身長=178.500000cm
体重=68.300000kg
*********構造体の代入
同じ型の構造体には、代入演算子を使用して一括で値を代入することが可能です。
サンプルプログラムを以下に示します。
#include <stdio.h>
struct student{
char name[20];
int age;
double height;
double weight;
};
int main(void){
struct student v1={"Yamada Taro",20,179.5,70.5};
struct student array1[5]={
{"Yamada Taro",20,180.5,75.0},
{"Suzuki Ichiro",21,170.5,65.0},
{"Yamada Hanako",22,160.5,55.0},
{"Sato Jiro",18,175.5,68.0},
{"Hayashi saburo",19,178.5,68.3}
};
int count;
struct student v2,array2[5];
count = sizeof(array1) / sizeof(struct student) ;
v2 = v1;
for(int i=0;i<count;i++){
array2[i] = array1[i];
}
printf("名前=%s\n",v2.name);
printf("年齢=%d歳\n",v2.age);
printf("身長=%fcm\n",v2.height);
printf("体重=%fkg\n",v2.weight);
printf("*********\n");
for(int i=0;i<count;i++){
printf("名前=%s\n",array2[i].name);
printf("年齢=%d歳\n",array2[i].age);
printf("身長=%fcm\n",array2[i].height);
printf("体重=%fkg\n",array2[i].weight);
printf("*********\n");
}
return 0;
}v2=v1; array2[i]=array1[i];のように代入演算子を使用し一括で代入できます。ただし、配列の場合は、配列の各要素に対して代入を行うことができますが、array2 = array1とはできません。
実行結果
名前=Yamada Taro
年齢=20歳
身長=179.500000cm
体重=70.500000kg
*********
名前=Yamada Taro
年齢=20歳
身長=180.500000cm
体重=75.000000kg
*********
名前=Suzuki Ichiro
年齢=21歳
身長=170.500000cm
体重=65.000000kg
*********
名前=Yamada Hanako
年齢=22歳
身長=160.500000cm
体重=55.000000kg
*********
名前=Sato Jiro
年齢=18歳
身長=175.500000cm
体重=68.000000kg
*********
名前=Hayashi saburo
年齢=19歳
身長=178.500000cm
体重=68.300000kg
*********関数の引数
構造体は通常の変数と同様に、「値渡し」と「アドレス渡し」の方法で引数として指定できます。
構造体を受け取る関数は以下のように記述します。
戻り値型 関数名(struct 構造体名 引数名,,,,);1.値渡し
以下にサンプルプログラムを示します。
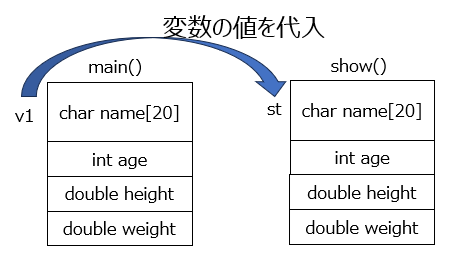
show()関数は仮引数stを受け取り、構造体の中身を表示します。
値渡しは実引数v1の値をshow()側の仮引数stにコピーしています。
#include <stdio.h>
struct student{
char name[20];
int age;
double height;
double weight;
};
void show(struct student st){
printf("名前=%s\n",st.name);
printf("年齢=%d歳\n",st.age);
printf("身長=%fcm\n",st.height);
printf("体重=%fkg\n",st.weight);
printf("*********\n");
}
int main(void){
struct student v1={"Yamada Taro",20,180.5,75.0};
show(v1);
return 0;
}このサンプルでは関数の引数は構造体一つだけですが、複数の構造体を引数として使用したり、構造体以外の型を組み合わせて引数に渡すことも可能です。
show()関数へは引数を値で渡すため、その関数内で構造体のメンバにアクセスする際はドット演算子(.)を使用します。
2.アドレス渡し
以下にサンプルプログラムを示します。
show()関数は、構造体studentのポインタ変数を引数とし、その構造体の内容を表示します。
アドレス渡しは、値渡しのように構造体の内容をコピーするのではなく、アドレスのみを渡すため、より効率的です。
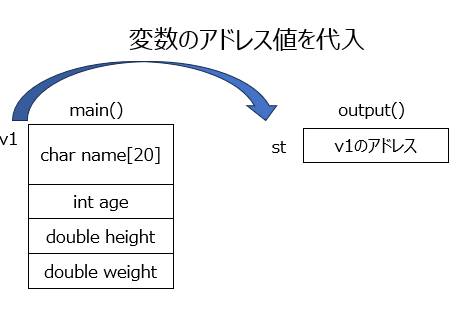
構造体ポインタ変数名->メンバ名ポインタ変数の構造体の各メンバにアクセスする場合、アロー演算子(->)を使います。
#include <stdio.h>
struct student{
char name[20];
int age;
double height;
double weight;
};
void output(struct student *st){
printf("名前=%s\n",st->name);
printf("年齢=%d歳\n",st->age);
printf("身長=%fcm\n",st->height);
printf("体重=%fkg\n",st->weight);
printf("*********\n");
}
void chgAge(STUDENT *st,int age){
st->age = age;
}
int main(void){
struct student v1={"Yamada Taro",20,180.5,75.0};
output(&v1);
chgAge(&v1, 25);
output(&v1);
return 0;
}アドレス渡しのため、関数内でメンバの値を変更した場合、呼び出し元の値も変更されます。
実行結果
名前=Yamada Taro
年齢=20歳
身長=178.500000cm
体重=75.500000kg
*********
名前=Yamada Taro
年齢=25歳
身長=178.500000cm
体重=75.500000kg
*********関数の戻り値
構造体以外の型同様に、関数の戻り値として構造体を戻すこともできます。
サンプルプログラムを以下に示します。
このサンプルでは、関数input()内部で、構造体の変数を宣言し値を代入後、戻り値として構造体の変数を返しています。
#include <stdio.h>
#include <string.h>
struct student{
char name[20];
int age;
double height;
double weight;
};
void show(struct student *st){
printf("名前=%s\n",st->name);
printf("年齢=%d歳\n",st->age);
printf("身長=%fcm\n",st->height);
printf("体重=%fkg\n",st->weight);
printf("*********\n");
}
struct student input(){
struct student st;
strcpy(st.name,"Yamada Taro");
st.age=20;
st.height = 178.5;
st.weight = 75.5;
return st;
}
int main(void){
struct student v1;
v1 = input();
show(&v1);
return 0;
}v1 = input()において、関数input()で返却した構造体の値をv1に代入しています。
実行結果
名前=Yamada Taro
年齢=20歳
身長=178.500000cm
体重=75.500000kg
*********
共用体
共用体は、構造体と同様に複数のデータ型を定義することができますが、異なるデータ型を同一のメモリ領域で使用する特性を持っています。たとえば、4バイトのメモリを1つのint型として使用するか、または4つのchar型として使用することが可能になります。
共用体の定義
共用体は以下のように定義されます。
union 共用体名{
型1 変数名1;
型2 変数名2;
;
};unionを使用して、{}で囲んだ中にメンバ変数とその型を宣言します。
末尾に;(セミコロン)を付けます。
共用体は、宣言で「struct」を「union」に置き換える以外、宣言の方法や使用方法は構造体とまったく同じです。
共用体と構造体について
C言語において、構造体と共用体は両方とも複数の異なるデータ型を一つにまとめる手段です。構造体は各データに名前(メンバー名)をつけ、個別のメモリ領域に保存します。共用体は全てのデータを同一のメモリ領域に割り当て、一つのデータのみを扱います。
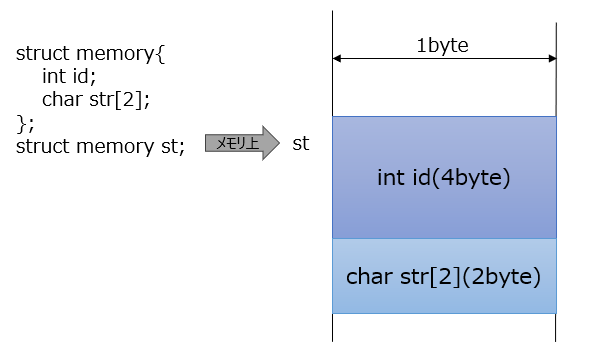
struct memory{
int id;
char str[2];
}
struct memory st;
構造体memoryの変数stを宣言すると、メモリ上では以下のように確保されます。
union memory1{
int id;
char str[2];
}
union memory1 ut;
共用体memory1の変数utを宣言すると、メモリ上では次のように確保されます。
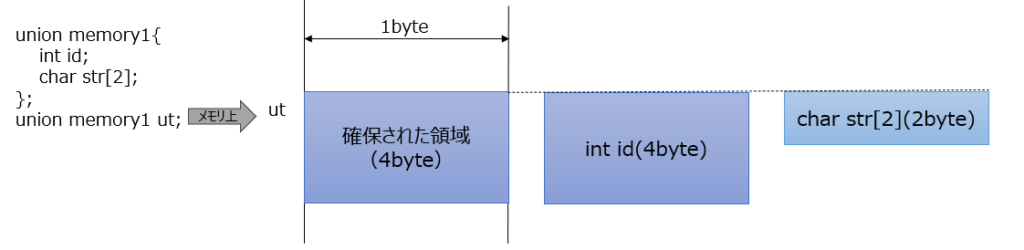
共用体においては、全てのメンバが同一のアドレスを共有している点が構造体と異なります。また、共用体に割り当てられるメモリのサイズは、その中で最も大きなメンバのサイズによって決定されます。
共用体の変数の利用例・初期化
変数は構造体と同じように初期化することが可能です。しかし、共用体では定義された最初のメンバにのみ値を格納できます。
uinon 共用体名 変数名={値1、値2,,,};以下のサンプルプログラムは、int型の変数とchar型の2要素配列をメンバとする共用体を定義し、int型の変数を初期化する場合とchar型の配列の値を変更した場合に、それぞれのメンバの値を表示するものです。
#include <stdio.h>
union memory{
int id;
char str[2];
};
int main(void){
union memory ut={1};
printf("ut.id=%x\n",ut.id);
for(int i=0;i<2;i++){
printf("ut.str[%d]=%x\n",i,ut.str[i]);
}
printf("*******\n");
ut.str[0]=0x55;
ut.str[1]=0x66;
printf("ut.id=%x\n",ut.id);
for(int i=0;i<2;i++){
printf("ut.str[%d]=%x\n",i,ut.str[i]);
}
return 0;
}
実行結果
ut.id=1
ut.str[0]=1
ut.str[1]=0
*******
ut.id=6655
ut.str[0]=55
ut.str[1]=66
実行結果から、異なるデータ型の値が同一のメモリ領域で共有されていることが確認できます。
typedef宣言について
C言語では、既存の型に別名を付けることができる機能が存在します。
typedef 既存の型 別名;この機能を使えば、structを付けなくても、構造体の変数を宣言することができます。
例えば、構造体型に別名を付ける場合、以下のように記述します。
typedef struct {
型1 変数名1,
型2 変数名2,
;
} 別名;先に紹介したサンプルプログラムをtypedefを利用したソースに書き換えてみます。
#include <stdio.h>
#include <string.h>
typedef struct{
char name[20];
int age;
double height;
double weight;
} STUDENT;
void show(STUDENT *st){
printf("名前=%s\n",st->name);
printf("年齢=%d歳\n",st->age);
printf("身長=%fcm\n",st->height);
printf("体重=%fkg\n",st->weight);
printf("*********\n");
}
STUDENT input(){
STUDENT st;
strcpy(st.name,"Yamada Taro");
st.age=20;
st.height = 178.5;
st.weight = 75.5;
return st;
}
int main(void){
STUDENT v1;
v1 = input();
show(&v1);
return 0;
}
構造体を定義する際には、typedefを使用して構造体名を短く書くことが一般的です。
別名は変数名や関数名と同様の命名規則に従いますが、英語の大文字がよく使われます。これは型名を際立たせ、コードの可読性を高めるためです。ただし、これは慣習に過ぎず、小文字を使用することもできます。
もちろん、typedefは構造体だけではなく、unionや他のデータ型でも使用できます。
以下は、unsigned char をBYTE、unionをINT_CHARと別名を付けたサンプルプログラムです。
#include <stdio.h>
typedef unsigned char BYTE;
typedef union{
int id;
BYTE str[2];
} INT_CHAR;
int main(void){
INT_CHAR ut={1};
printf("ut.id=%x\n",ut.id);
for(int i=0;i<2;i++){
printf("ut.str[%d]=%x\n",i,ut.str[i]);
}
printf("*******\n");
ut.str[0]=0x55;
ut.str[1]=0x66;
printf("ut.id=%x\n",ut.id);
for(int i=0;i<2;i++){
printf("ut.str[%d]=%x\n",i,ut.str[i]);
}
return 0;
}共用体と構造体の入れ子
構造体と共用体を組み合わせることで、構造体内に共用体を配置したり、共用体内に構造体を配置したりすることが可能です。これは、構造体のメンバーの型を柔軟に変更することや、共用体のメンバーの意味をより明確にすることに役立ちます。
構造体と共用体の組み合わせの例を以下に示します。
1.構造体の中に共用体を定義するサンプル
#include <stdio.h>
#include <string.h>
struct person {
char name[20]; // 名前
union { // 性別と年齢を共用体で表す
char gender; // 性別(M:男性、F:女性)
int age; // 年齢
} info;
};
int main(void){
struct person p;
strcpy(p.name,"Yamada Taro");
p.info.gender='M';
printf("name=%s : gender=%c\n", p.name,p.info.gender);
p.info.age=25;
printf("name=%s : gender=%c : age=%d\n", p.name,p.info.gender,p.info.age);
}実行結果
name=Yamada Taro : gender=M
name=Yamada Taro : gender= : age=25
この例では、構造体内に共用体を配置し、性別と年齢を同一のメモリ領域に格納しています。これにより構造体のサイズを削減できますが、性別と年齢を同時には使用できません。
「person p; p.info.gender = ‘M’; p.info.age = 25;」とすると、「p.info.gender」の値は上書きされてしまいます。
2.共用体の中に構造体を定義したサンプル
#include <stdio.h>
#include <string.h>
union shape {
struct { // 円を表す構造体
double radius; // 半径
} circle;
struct { // 四角形を表す構造体
double length; // 長さ
double width; // 幅
} rectangle;
};
int main(void){
union shape s;
s.circle.radius = 8.0;
printf("radius=%.1f\n",s.circle.radius);
s.rectangle.length=10.5;
s.rectangle.width=5.7;
printf("radius=%.1f\n",s.circle.radius);
printf("length=%.1f : width=%.1f\n",s.rectangle.length,s.rectangle.width);
return 0;
}実行結果
radius=8.0
radius=10.5
length=10.5 : width=5.7この例では、共用体に構造体を格納して、円と四角形を同一のメモリ領域に収めています。これにより、共用体のメンバーの型を柔軟に変更することが可能ですが、円と四角形を同時には使用できません。
「shape s; s.circle.radius = 10; s.rectangle.length = 20;」とすると、「s.circle.radius」の値は上書きされてしまいます。
構造体と共用体を組み合わせることは、以下のような場面で有用です。
- データの型や意味を柔軟に変更する必要がある場合、例えば文字コードやネットワークパケットなど、共用体に構造体を組み込むことでビット単位の操作や、意味のある単位でのデータ分割が可能です。
- データのサイズを節約する必要がある場合、例えば性別や色などは構造体内に共用体を使用することで、1バイト未満のメモリ領域に収めることが可能です。
構造体と共用体を組み合わせることは、データ構造を柔軟に表現する便利な手法です。ただし、一度に使用できるデータは一つのみである点に留意が必要です。
共用体のメンバーが上書きされないように、適切な初期化と代入が必要です。
ビットフィールド
C言語のビットフィールドは、構造体のメンバーにビット単位でメモリを割り当てる機能であり、メモリ使用量を最適化し、特定のビットパターンのデータを効率的に処理することが可能です。
たとえば、年月日を構造体で定義した場合とビットフィールドで定義した場合のバイト数の比較をしてみます。
#include <stdio.h>
typedef struct{
int day;
int month;
int year;
} DATE_1;
typedef struct{
unsigned int day:5;// 1から31
unsigned int month:4; //1から12
unsigned int year:12; //1から4095
} DATE_2;
int main(void)
{
printf("DATE_1:%lu(byte)\n",sizeof(DATE_1));
printf("DATE_2:%lu(byte)\n",sizeof(DATE_2));
}実行結果
DATE_1:12(byte)
DATE_2:4(byte)DATE_1は通常の構造体で、DATE_2はビットフィールドを使用した構造体です。
DATE_2のdayフィールドには5ビットを割り当て、1から31までの値、monthフィールドには4ビットを割り当て、1から12までの値、yearフィールドには12ビットを割り当て、0から4095までの値を格納できます。
DATE_1はint型のメンバを3個確保しているため、12byteという結果になりました。
ビットフィールドは、通常、基本データ型(int, long など)の境界内でパックされます。
構造体全体のサイズは、使用される基本データ型の倍数になるように調整され、unsigned int を使用する場合、通常は4バイト(32ビット)単位でパックされます。
したがって、DATE_2は4byteという結果になっています。
ビットフィールドの利点
メモリ効率: ビットフィールドを使用することで、メモリ使用量を最小限に抑えることができます。
可読性: ビット操作を直接行う代わりにビットフィールドを使用することで、コードの可読性が向上します。
型安全性: コンパイラは、各フィールドに割り当てられたビット数を超える値が代入されないようにチェックします。
注意点
ビットフィールドのメモリレイアウトは、コンパイラや環境に依存する場合があります。
ビットフィールドのメンバーのアドレスを取得することはできません。
一部のプラットフォームでは、ビットフィールドへのアクセスが通常のメンバーよりも遅くなる可能性があります。
ビットフィールドは、限られたビット数で情報を効率的に表現する必要がある場合や、ハードウェアレジスタを直接操作する場合に特に有用です。
適切に使用することで、コードの効率性と可読性を向上させることができます。


{kind=link}
コメント