
この章では、機械学習やデータ分析を行う上で、非常に重要な役割を果たすDataFrameについて、基本的な使い方について説明します
DataFrameとは
DataFrameは、Pythonのデータ分析ライブラリであるpandasの中の主要なデータ構造の一つで、データを行と列で表した表形式のデータ構造です。表計算ソフトのスプレッドシートのような2次元のデータイメージです
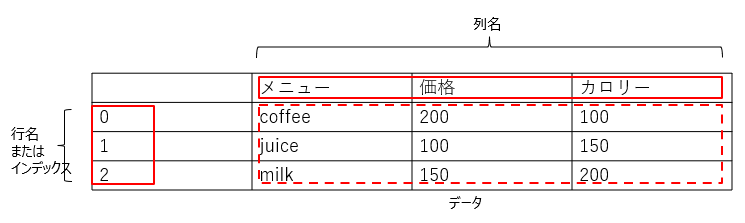
次のようなイメージで行と列が存在し、それぞれの列ごとに文字列や数値などのデータが格納されています
また、列には列名、行には行名またはインデックスが付けられています
DataFrameの作成方法
DataFrameは以下のように作成します
import pandas as pd
変数 = pd.DataFrame(data = 格納するデータ, index = 行名, columns = 列名)
dataはDataFrameに格納するデータで、リストや辞書、NumPy配列など、様々なデータを渡すことができますindexは各行の行名をリストなどで指定します(省略した場合は1行目から0,1,2と連番がふられます)columnsは各列の列名をリストなどで指定します(省略した場合は、1列目から0,1,2と連番がふられます)
import pandas as pdDataFrameを使用する場合、pandasライブラリをインポートします
pdとしてpandasをimportするという意味で慣例的にこのように記載します
辞書から作成する方法
辞書を定義しDataFrameを作成するサンプルプログラムを以下に示します
import pandas as pd
data = {
'メニュー':['coffee','juice','milk'],
'値段':[200,100,150],
'カロリー':[100,150,200]
}
df = pd.DataFrame(data)
print(df)
実行結果
メニュー 値段 カロリー
0 coffee 200 100
1 juice 100 150
2 milk 150 200
リストから作成する方法
リストを定義しDataFrameを作成するサンプルプログラムを以下に示します
l = [10,20,30]
df = pd.DataFrame(l,columns=["value"])
print(df)
実行結果
value
0 10
1 20
2 30
列名を[“value”]と定義しています
ndarrayから作成する方法
Numpyで作成したndarrayからDataFrameをサンプルプログラムを以下に示します
import numpy as np
arr = np.array([[1,2,3],[4,5,6],[7,8,9]])
df = pd.DataFrame(arr,columns=['a','b','c'])
print(df)
実行結果
a b c
0 1 2 3
1 4 5 6
2 7 8 9
CSVファイルから作成する方法
CSV形式のファイルを以下のように記述することで、読み込むことができます
データフレーム = pd.read_csv(ファイル名,encoding=文字エンコーディング)以下にcsvファイル(kadai2.csv)を読み込むサンプルプログラムを示します
使用するkadai2.csvは以下のプログラムを用いて作成しました
import random
import csv
csvlist = []
for i in range(100):
dt = []
dt.append(random.randint(1,6))
for j in range(3):
dt.append(random.randint(0,100))
csvlist.append(dt)
with open("kadai2.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["クラス","国語","算数","社会"])
writer.writerows(csvlist)df = pd.read_csv('kadai2.csv',encoding='utf-8')
df.head(5)
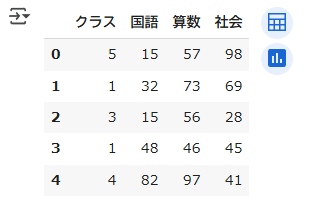
df.head(5)読み込んだDataFrameの先頭から5行分を表示する関数です
DataFrameの最初から指定した行を表⽰するには、headメソッド(最初から指定した⾏分表⽰)、
最後から指定した行を表示するには、tailメソッド(最後から指定した⾏分表⽰)を使⽤します
⾏数を省略すると5⾏分表⽰します
DataFrameの基本操作
列を取得
以下のように記載することで、特定の列を抽出できます
データフレーム['列名'] 前述したkadai2.csvで取得したサンプルプログラムを以下に示します
df['国語']

また、下記のように書くことで最初から5行分を表示することができます
df['国語'].head(5)複数の列をまとめて取得する場合は、以下のように記述します
データフレーム[[列名1,列名2,列名3,...]]前述したkadai2.csvで取得したサンプルプログラムを以下に示します
df[['国語','社会']]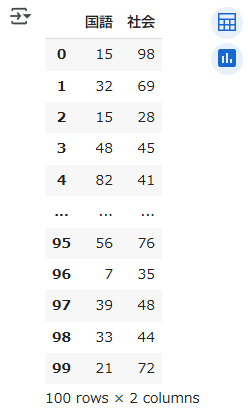
条件に基づいた要素の取得
データフレームの中から、ある条件にあう要素だけを取得することもできます
データフレーム[条件式]前述したkadai2.csvから国語の点数が60より大きく、かつ、社会の点数が60より大きいデータを抽出し最後の5行を表示するサンプルプログラムを以下に示します
df[ (df['国語']>60) & (df['社会']>60) ].tail(5)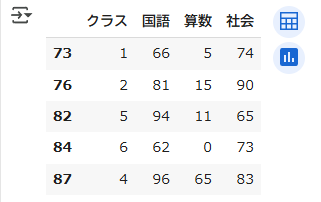
合計や最大値・最小値を取得
・特定の列の合計を取得
以下のように記載することで、指定した列の合計値を計算することができます
データフレーム[列名].sum()前述したkadai2.csvから算数の列を加算するサンプルプログラムを以下に示します
df['算数'].sum()実行結果
5662また、列名をリストで指定することで指定した各列の合計をそれぞれ計算することもできます
columns_sum = ['算数','社会']
total_sum = 0;
for column in columns_sum:
total_sum += df[column].sum()
print(total_sum)
実行結果
10893・最大値・最小値を取得
以下のように、max関数は最大値、min関数は最小値を計算することができます
データフレーム[列名].max() # 列の最大値
データフレーム[列名].min() # 列の最小値前述したkadai2.csvから社会の最小値、最大値を取得するサンプルプログラムを以下に示します
print(df['社会'].min())
print(df['社会'].max())実行結果
0
99・ある列の最大値を持つ行を取得する
以下のプログラムでは、国語の最大値をもつ行を取得しています
df[df['国語'] == df['国語'].max()]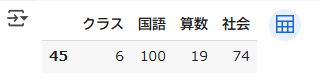
ある列の最大値を持つインデックスを取得し、特定の列の値を取得したい場合があります
そのときは、idxmax()、loc()関数を利用して以下のように記述します
変数1=データフレーム['列名'].idxmax()
変数2=データフレーム.loc[変数1,'列名']変数1=データフレーム['列名'].idxmax()max関数は最大値そのものを返しますが、idxmax()は 最大値を持つ行または列のインデックスを返します
開始値は0です
変数2=データフレーム.loc[変数1,'列名']インデックスを使ってloc関数を使用し、インデックスに対応する列名が持つ値を取得しています
loc関数は、行のインデックス番号と列のラベルを指定して、要素を参照するための方法の1つです
前述したkadai2.csvを使用し、算数の最大値を持つ行の国語、算数、社会、の値を表示するサンプルプログラムを以下に示します
max_sansu_index = df['算数'].idxmax()
print(max_sansu_index)
tensu = df.loc[max_sansu_index,'国語']
print("国語:"+str(tensu))
tensu = df.loc[max_sansu_index,'算数']
print("算数:"+str(tensu))
tensu = df.loc[max_sansu_index,'社会']
print("社会:"+str(tensu))
12
国語:13
算数:100
社会:56
新たに列を追加する
データフレームに新しい列を追加する場合、以下のように記述します
データフレーム[新しい列名] = 値前述したkadai2.csvにおいて、合計、平均という新しい列名を作成し、各行ごとに合計値および平均値を計算するサンプルプログラムを以下に示します
df['合計'] = df['算数'] + df['社会'] + df['国語']
df['平均'] = df['合計']/3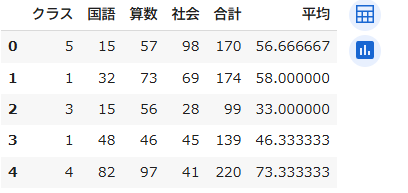
初めから5行分表示した結果です
また、以下のように記述することもできます
label = ['国語','算数','社会']
df['合計']=df[label].sum(axis=1)axis=1と引数を渡すことで列ごとの和を計算することができます
データの集計
指定した列名をもとにグループごとに集計する方法もあります
# グループごとの合計
データフレーム.groupby('列名').sum()
# グループごとの平均値
データフレーム.groupby('列名').mean()
前述したkadai2.csvにおいて、クラスごとの合計値、平均値を計算するサンプルプログラムを以下に示します
df.groupby('クラス').sum()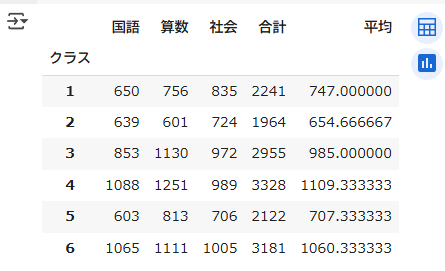
df.groupby('クラス').mean()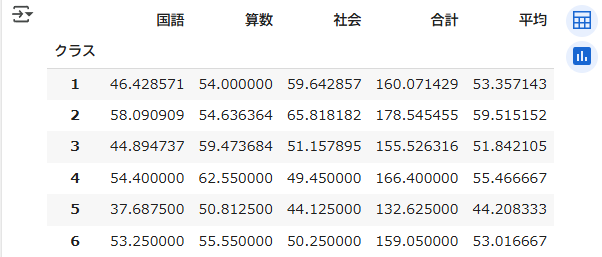
【演習問題】
以下の手順に従って、演習を行いましょう
- 次のプログラムを実行しkadai7.csvというファイルを作成します
データは地域(area)、性別(gender)、年齢(age)、身長(height)、体重(weight)を持っているデータです
import pandas as pd
import numpy as np
area_list = ["北海道", "東北", "関東", "中部", "近畿", "中国", "四国", "九州・沖縄"]
gender_list = ["男", "女"]
df = pd.DataFrame({'area': np.random.choice(area_list, 30),
'gender': np.random.choice(gender_list, 30),
'age': np.random.randint(18,80,30),
'height': np.random.randint(150,200,30),
'weight': np.random.randint(40,100,30)
})
df.head()
df.to_csv('kadai7.csv')
- 1で作成したkadai7.csvを読み込み、先頭から5行分表示してみましょう
- 年齢(age)の最大値と最小値を取得してみましょう
実行結果
20
79- 体重(weight)が一番多いインデックスと地域名を取得してみましょう
実行結果
3
近畿- 身長(height)の平均値を計算してみましょう
実行結果
170.66666666666666

{kind=link}
コメント