
この章では構造体、共用体、列挙体について説明をしていきます
構造体
構造体とは、複数の異なる型のデータをひとまとめにしたユーザー定義のデータ型です
各メンバは独立したメモリ領域を持ちます
structキーワードを使用し、以下のように定義します
struct 構造体名{
型1 変数名1;
型2 変数名2;
;
};構造体のメンバーにはドット演算子(.)を使って変数名.メンバ名と記述することで、アクセスします
以下に、構造体の例を示します
– 構造体の例1:学生の情報を格納する構造体
#include <string>
#include <iostream>
int main(){
// 構造体の定義
struct Student {
std::string name; // 名前
int age; // 年齢
double score; // 成績
};
// 構造体の変数を宣言
Student s1;
// 構造体のメンバに値を代入
s1.name = "Alice";
s1.age = 20;
s1.score = 90.5;
// 構造体のメンバにアクセス
std::cout << "Name: " << s1.name << std::endl;
std::cout << "Age: " << s1.age << std::endl;
std::cout << "Score: " << s1.score << std::endl;
return 0;
}// 構造体の変数を宣言
Student s1;これは Student 型の変数 s1 を宣言しています
これにより、s1 という名前で Student 構造体の実体(オブジェクト)がメモリ上に作成されます
C言語で構造体の変数を宣言する場合は、struct Student s1; のように struct キーワードを省略せずに記述する必要がありました
C++では、構造体のタグ名が型名としても扱われるため、struct キーワードを省略できます
– 構造体の例2:複素数を表す構造体
#include <iostream>
int main(){
// 構造体の定義
struct Complex {
double real; // 実部
double imag; // 虚部
};
// 構造体の変数を宣言
Complex c1, c2;
// 構造体の変数に値を代入
c1.real = 1.0;
c1.imag = 2.0;
c2.real = 3.0;
c2.imag = 4.0;
// 構造体の変数を演算
Complex c3;
c3.real = c1.real + c2.real;
c3.imag = c1.imag + c2.imag;
// 構造体の変数を表示
std::cout << "c1 = " << c1.real << " + " << c1.imag << "i" << std::endl;
std::cout << "c2 = " << c2.real << " + " << c2.imag << "i" << std::endl;
std::cout << "c3 = " << c3.real << " + " << c3.imag << "i" << std::endl;
return 0;
}共用体
共用体とは、複数の異なる型のデータを同じメモリ領域に割り当てたユーザー定義のデータ型で、同時に有効なメンバは一つだけです
例えば、int型とchar型のデータを同じメモリに格納できますが、一度に一つのデータしか有効になりません
共用体は以下のようにunionキーワードを用いて以下のように定義します
union 共用体名{
型1 変数名1;
型2 変数名2;
;
};共用体は、宣言で「struct」を「union」に置き換える以外、宣言の方法や使用方法は構造体とまったく同じです
– 共用体の例1:int型とchar型のデータを共有する共用体
#include <iostream>
int main(){
// 共用体の定義
union Data {
int i; // int型のメンバ
char c; // char型のメンバ
};
// 共用体の変数を宣言
Data d1;
// 共用体のメンバに値を代入
d1.i = 65;
// 共用体のメンバにアクセス
std::cout << "i = " << d1.i << std::endl; // 65
std::cout << "c = " << d1.c << std::endl; // A
// 共用体のメンバの値を変更
d1.c = 'B';
// 共用体のメンバにアクセス
std::cout << "i = " << d1.i << std::endl; // 66
std::cout << "c = " << d1.c << std::endl; // B
return 0;
}// 共用体の変数を宣言
Data d1;構造体のときと同様に、C言語で共用体の変数を宣言する場合は、union Data di; のように union キーワードを省略せずに記述する必要がありました
C++では、共用体のタグ名が型名としても扱われるため、union キーワードを省略できます
– 共用体の例2:RGBカラーを表す共用体
#include <iostream>
int main(){
// 共用体の定義
union Color {
int value; // int型のメンバ
struct { // 構造体型のメンバ
unsigned char r; // 赤
unsigned char g; // 緑
unsigned char b; // 青
} rgb;
};
// 共用体の変数を宣言
Color c1;
// 共用体のメンバに値を代入
c1.value = 0xFF0000; // 赤色
// 共用体のメンバにアクセス
std::cout << "value = " << std::hex << c1.value << std::endl; // FF0000
std::cout << "r = " << std::hex << (int)c1.rgb.r << std::endl; // FF
std::cout << "g = " << std::hex << (int)c1.rgb.g << std::endl; // 0
std::cout << "b = " << std::hex << (int)c1.rgb.b << std::endl; // 0
// 共用体のメンバの値を変更
c1.rgb.g = 0xFF; // 緑を加える
// 共用体のメンバにアクセス
std::cout << "value = " << std::hex << c1.value << std::endl; // FFFF00
std::cout << "r = " << std::hex << (int)c1.rgb.r << std::endl; // FF
std::cout << "g = " << std::hex << (int)c1.rgb.g << std::endl; // FF
std::cout << "b = " << std::hex << (int)c1.rgb.b << std::endl; // 0
return 0;
}– 共用体の例3:ビットフィールドを表す共用体
#include <iostream>
int main(){
// 共用体の定義
union BitField {
int value; // int型のメンバ
struct { // 構造体型のメンバ
unsigned int bit0 : 1; // ビット0
unsigned int bit1 : 1; // ビット1
unsigned int bit2 : 1; // ビット2
unsigned int bit3 : 1; // ビット3
unsigned int bit4 : 1; // ビット4
unsigned int bit5 : 1; // ビット5
unsigned int bit6 : 1; // ビット6
unsigned int bit7 : 1; // ビット7
} bits;
};
// 共用体の変数を宣言
BitField b1;
// 共用体のメンバに値を代入
b1.value = 0x55; // 01010101
// 共用体のメンバにアクセス
std::cout << "value = " << std::hex << b1.value << std::endl; // 55
std::cout << "bit0 = " << b1.bits.bit0 << std::endl; // 1
std::cout << "bit1 = " << b1.bits.bit1 << std::endl; // 0
std::cout << "bit2 = " << b1.bits.bit2 << std::endl; // 1
std::cout << "bit3 = " << b1.bits.bit3 << std::endl; // 0
std::cout << "bit4 = " << b1.bits.bit4 << std::endl; // 1
std::cout << "bit5 = " << b1.bits.bit5 << std::endl; // 0
std::cout << "bit6 = " << b1.bits.bit6 << std::endl; // 1
std::cout << "bit7 = " << b1.bits.bit7 << std::endl; //
return 0;
}構造体と共用体の違い
構造体と共用体のメモリ割り当てに関する主な違いを以下の表にまとめます
| 特徴 | 構造体(Struct) | 共用体(Union) |
|---|---|---|
| メモリ割り当て | 各メンバに独立した領域を割り当てる | 全てのメンバで同じ領域を共有する |
| サイズ | メンバのサイズの合計(アラインメントによる調整あり) | 最も大きなメンバのサイズ(アラインメントによる調整あり) |
| 同時利用 | 全てのメンバを同時に利用可能 | 一度に一つのメンバのみ利用可能 |
| データへの影響 | あるメンバの変更は他のメンバに影響しない | あるメンバへの代入は他のメンバの値を上書きする |
| 主な用途 | 関連する独立したデータをまとめる | メモリ節約、データの再解釈 |
構造体と共用体の比較サンプル
- 構造体
整数と文字列を持った構造体を定義します
#include <string>
#include <iostream>
#include <iomanip>
int main(){
struct memory{
int id;
char str[2];
} ;
memory st;
std::cout << "struct size=" << sizeof(memory) << std::endl; // 8
std::cout << "id=" << &st.id << std::endl; // 0x7ffddf5ecd8c0
std::cout << "str=" << &st.str << std::endl; // 0x7ffddf5ecd8c4
st.id=10;
st.str[0]='A';
st.str[1]='\0';
std::cout << "id=" << std::hex << std::showbase << std::setw(4)
<< st.id << std::endl; // 0xa
std::cout << "str=" << std::hex << std::showbase << std::setw(4)
<< static_cast<unsigned int>(st.str[0])
<< static_cast<unsigned int>(st.str[1]) << std::endl; // 0x410
return 0;
}この構造体のメモリ領域は以下のようになっています

std::cout << "id=" << &st.id << std::endl; // 0x7ffddf5ecd8c0
std::cout << "str=" << &st.str << std::endl; // 0x7ffddf5ecd8c4この結果から、idとstrのメモリ領域は異なっていることがわかります
std::cout << "struct size=" << sizeof(memory) << std::endl; // 8idとstrは独立した領域であるため、構造体のサイズはidとstrの両方が保持できる大きさが確保されます
st.id=10;
st.str[0]='A';
st.str[1]='\0';
std::cout << "id=" << std::hex << std::showbase << std::setw(4)
<< st.id << std::endl; // 0xa
std::cout << "str=" << std::hex << std::showbase << std::setw(4)
<< static_cast<unsigned int>(st.str[0])
<< static_cast<unsigned int>(st.str[1]) << std::endl; // 0x410id、strはそれぞれメモリ領域が異なるため、id、strに値を代入すると、それぞれの値が保持されます
- 1の構造体をunionで定義したサンプル
共用体を数値または文字列のどちらかを格納できる変数として使用するイメージです
int main(void){
union memory{
int id;
char str[2];
} ;
memory st;
std::cout << "struct size=" << sizeof(memory) << std::endl; // 4
std::cout << "id=" << &st.id << std::endl; // 0x7ffd3ddd32f4
std::cout << "str=" << &st.str << std::endl; // 0x7ffd3ddd32f4
st.id=10;
std::cout << "id=" << std::hex << std::showbase << std::setw(4)
<< st.id << std::endl; // 0xa
std::cout << "str=" << std::hex << std::showbase << std::setw(4)
<< static_cast<unsigned int>(st.str[0])
<< static_cast<unsigned int>(st.str[1]) << std::endl; // 0xa0
st.str[0]='A';
st.str[1]='\0';
std::cout << "id=" << std::hex << std::showbase << std::setw(4)
<< st.id << std::endl; // 0x41
std::cout << "str=" << std::hex << std::showbase << std::setw(4)
<< static_cast<unsigned int>(st.str[0])
<< static_cast<unsigned int>(st.str[1]) << std::endl; // 0x410
return 0;
}共用体の場合は以下のようなメモリ配置になっています
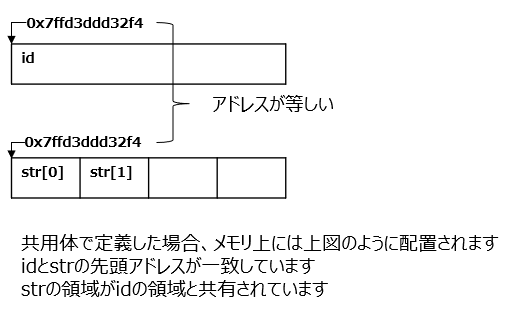
std::cout << "id=" << &st.id << std::endl; // 0x7ffd3ddd32f4
std::cout << "str=" << &st.str << std::endl; // 0x7ffd3ddd32f4共用体の場合、すべてのメンバが同じ領域を共有しています
そのため、idとstrの先頭アドレスが一致し、idとstrの領域が共有されています
std::cout << "struct size=" << sizeof(memory) << std::endl; // 4共用体のsizeofの結果は、intのサイズになっています
共用体のサイズは、一番大きいサイズを持つメンバであるintのサイズになっています
st.id=10;
std::cout << "id=" << std::hex << std::showbase << std::setw(4)
<< st.id << std::endl; // 0xa
std::cout << "str=" << std::hex << std::showbase << std::setw(4)
<< static_cast<unsigned int>(st.str[0])
<< static_cast<unsigned int>(st.str[1]) << std::endl; // 0xa0idに値を代入すると、代入していないstrの値も変わります
st.str[0]='A';
st.str[1]='\0';
std::cout << "id=" << std::hex << std::showbase << std::setw(4)
<< st.id << std::endl; // 0x41
std::cout << "str=" << std::hex << std::showbase << std::setw(4)
<< static_cast<unsigned int>(st.str[0])
<< static_cast<unsigned int>(st.str[1]) << std::endl; // 0x410一方、strの値を変更すると、idの値も変わりました
同じ領域を使用しているため、片方に書き込むともう片方にも影響が出ています
共用体の利用シーン
共用体の主な利用目的は、同じメモリ領域で異なる型のデータを扱いたい場合に、メモリの使用量を節約することです
特に、メモリ資源が限られた組み込みシステムなどで有効です
また、メモリ上の同じバイト列を異なるデータ型として解釈する(メモリの再解釈)といった用途にも用いられます
列挙型
列挙型とは、名前付きの整数定数の集合を表すユーザー定義のデータ型です
列挙型を定義するには、enumというキーワードを使い、以下のように定義します
enum 列挙型の名前{
列挙子1,
列挙子2
};例えば、以下のように季節を表す列挙型を定義できます
enum season { spring, summer, autumn, winter };ここで、seasonは列挙型の名前で、spring, summer, autumn, winterは列挙子です
デフォルトでは、springは0, summerは1というように、列挙型の値は0から始まる整数に対応します
必要に応じて、列挙型の値に任意の整数を割り当てることもできます
enum season { spring = 0, summer = 4, autumn = 8, winter = 12 };列挙型を定義したら、列挙型の変数を作ることができます
列挙型の変数は、列挙型の値のうちの一つだけを持つことができます
例えば、以下のように曜日を表す列挙型の変数を作って、値を代入できます
enum week { Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday };
week today;
today = Wednesday;列挙型は、限られた値の中から選択する必要がある場合に便利です
例えば、性別を表す変数には、男性か女性のどちらかの値しか持たせたくないでしょう
このような場合に、列挙型を使うと、コードが簡潔になり、エラーを防ぐことができます
また、列挙型はswitch文と組み合わせて使うのが、用途としては多い印象です


{kind=link}
コメント