
Pythonには数値計算を高速に行う「Numpy(ナムパイ)」というライブラリがあります
機械学習では大量の入力データでのデータ分析を行う際には、Numpyがよく使われます
この章では、Numpyの基礎的な使い方を説明します
NumPy配列(ndarray)
Numpyでは、多次元配列を基本的なデータ構造として操作するライブラリのため、Numpy独自のndarrayというデータ構造を演算に使います
ndarrayは以下の特徴があります
- NumPyの中心となるデータ構造
- 全ての要素が同じデータ型でなければならない
- ベクトル、行列、多次元配列を表現できる
ndarrayを作成するには、np.array() メソッドを使用します
import numpy as np
変数 = np.array(オブジェクト)
import numpy as npnpとしてnumpyをimportするという意味で慣例的にこのように記載します
変数 = np.array(オブジェクト) 引数オブジェクトにはリストやタプルを渡します
戻り値はnp.arrayで生成したインスタンスが返り変数として保持しています
1次元配列、2次元配列を作成したサンプルプログラムを以下に示します
# 1次元配列
arr1 = np.array([1,2,3])
print(type(arr1))
print(arr1)
# 2次元配列
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(type(arr2))
print(arr2)
実行結果
<class 'numpy.ndarray'>
[1 2 3]
<class 'numpy.ndarray'>
[[1 2 3]
[4 5 6]]
ファイルからのデータLoad
NumpyからCSVファイルを読み込んでndarrayを作成する方法もあり、loadtxt関数を利用し以下のように記述します
import numpy as np
変数 = np.loadtxt(ファイル名,delimiter=区切り文字,encoding=文字エンコーディング,skiprows=整数)
delimiterはcsvファイルの区切り文字を指定します
skiprowsは1行目からスキップする行数を指定します
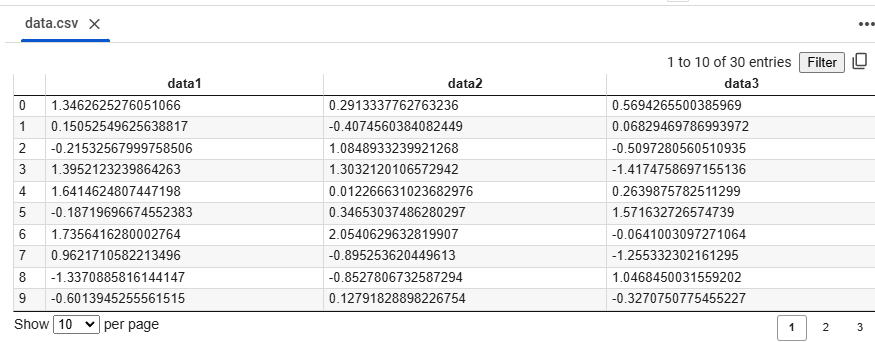
次のようなCSVファイルのdata.csvファイルを読み込むサンプルプログラムを以下に示します
data = np.loadtxt('./data.csv', delimiter=',',skiprows=1,encoding="utf-8")
print(type(data))
print(data)実行結果
<class 'numpy.ndarray'>
[[ 0. 1.34626253 0.29133378 0.56942655]
[ 1. 0.1505255 -0.40745604 0.0682947 ]
[ 2. -0.21532568 1.08489332 -0.50972806]
[ 3. 1.39521232 1.30321201 -1.41747587]
[ 4. 1.64146248 0.01226663 0.26398758]
[ 5. -0.18719697 0.34653037 1.57163273]
[ 6. 1.73564163 2.05406296 -0.06410031]
[ 7. 0.96217106 -0.89525362 -1.2553323 ]
[ 8. -1.33708858 -0.85278067 1.046845 ]
<略>
[25. -0.98116411 0.20668855 1.24457614]
[26. 0.52691362 3.26214759 0.19713629]
[27. -0.49444268 -1.17865946 1.18994441]
[28. -0.19957236 1.43460934 -0.05638495]
[29. -0.01240743 1.26909972 1.03244808]]
配列の属性
np.ndarrayには多数の属性がありますが、そのうちよく使われるものを以下に列挙します
- shape: 配列の形状をタプル型で表す(ex. (行数,列数)、(奥行,行数,列数)など)
- dtype: 配列のデータ型
- ndim: 配列の次元数
- size: 配列の要素数
2次元配列を定義しそれぞれの属性を表示するサンプルプログラムを以下に示します
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
print(arr.shape) # (2, 3)
print(arr.dtype) # int64
print(arr.ndim) # 2
print(arr.size) # 6
実行結果
[[1 2 3]
[4 5 6]]
(2, 3)
int64
2
6
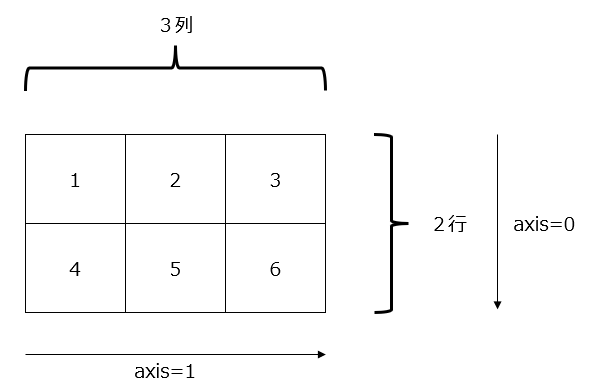
配列arrはこの図のように定義されています
axisとは配列の次元方向を指定するパラメータでshapeのインデックスに対応しています
3次元配列を定義しそれぞれの属性を表示するサンプルプログラムを以下に示します
import numpy as np
arr = np.array([
[
[1, 2, 3, 4],
[4, 5, 6, 7],
[0, 1, 2, 3]
],
[
[7, 8, 9, 0],
[1, 2, 3, 4],
[0, 1, 2, 3]
]
]
)
print(arr)
print(arr.shape) # (2, 3, 4)
print(arr.dtype) # int64
print(arr.ndim) # 3
print(arr.size) # 24
実行結果
[[[1 2 3 4]
[4 5 6 7]
[0 1 2 3]]
[[7 8 9 0]
[1 2 3 4]
[0 1 2 3]]]
(2, 3, 4)
int64
3
24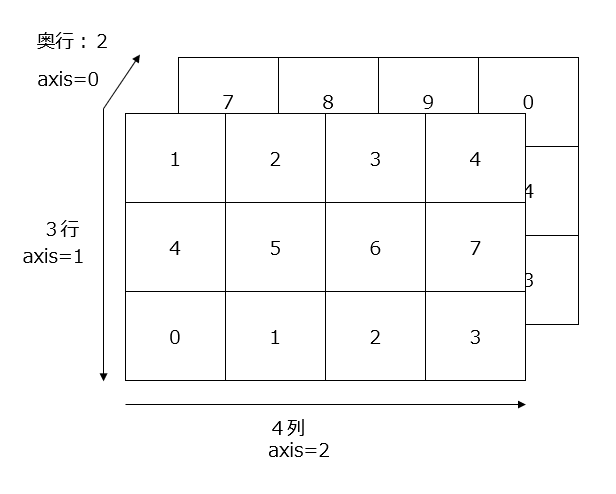
配列arrはこの図のように定義されています
配列の操作
インデックスで特定の要素にアクセス
Numpyの配列で特定の要素を取得するにはインデックスを使います
以下からは2次元配列においての方法を説明します
まず、特定の要素を取得するには以下のように記述します
配列[行インデックス][列インデックス]
配列[行インデックス,列インデックス]インデックスは0から始まります
前述したdata.csvデータを使って要素を取り出したサンプルプログラムを以下に示します
print(data[2,3]) 実行結果
-0.5097280560510935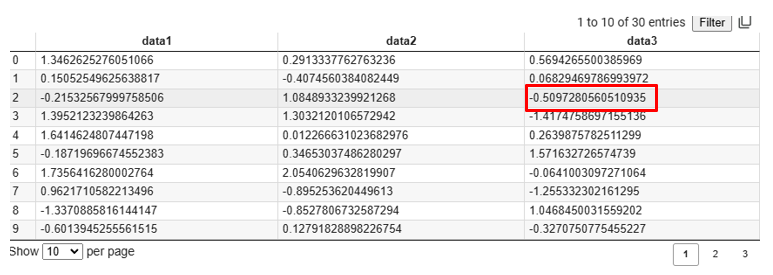
print(data[9,1])実行結果
-0.6013945255561515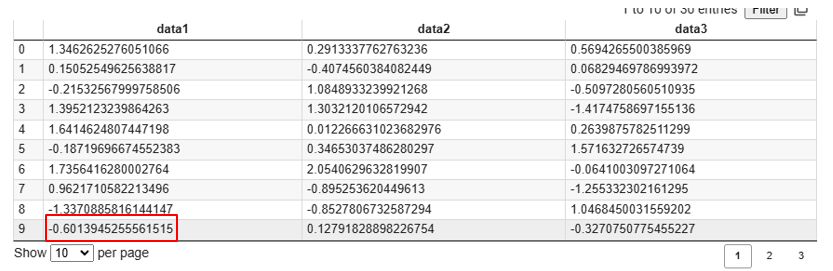
ある行や列を丸ごと取得したり、範囲を指定して取得するには次のように記述します
# 特定の行の取得
配列[行のインデックス]
#特定の列の取得
配列[:,列のインデックス]
配列[...,列のインデックス]
#配列の指定した範囲範囲
配列[開始行番号:終了行番号,開始列番号:終了列番号]
前述したdata.csvデータを使って要素を取り出したサンプルプログラムを以下に示します
# 行インデックスが3の行を取得
print(data[3])実行結果
[ 3. 1.39521232 1.30321201 -1.41747587]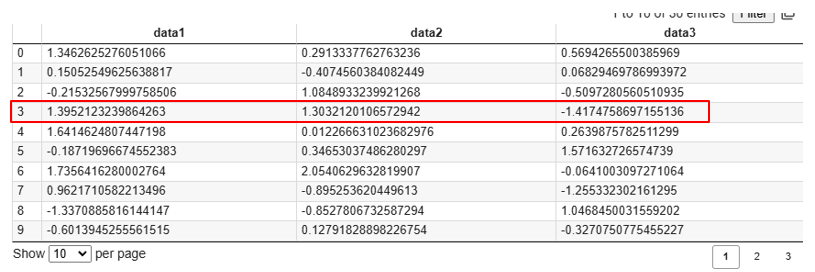
# 列インデックスが2の列を取得
print(data[:,2])[ 0.29133378 -0.40745604 1.08489332 1.30321201 0.01226663 0.34653037
2.05406296 -0.89525362 -0.85278067 0.12791829 -0.08572513 0.3871476
1.7228992 -0.1110288 -2.32578498 -0.9189456 0.93131263 1.9395611
0.58332947 0.33358372 -0.36221739 2.35893798 -1.18158312 -1.70294634
-2.19105821 0.20668855 3.26214759 -1.17865946 1.43460934 1.26909972]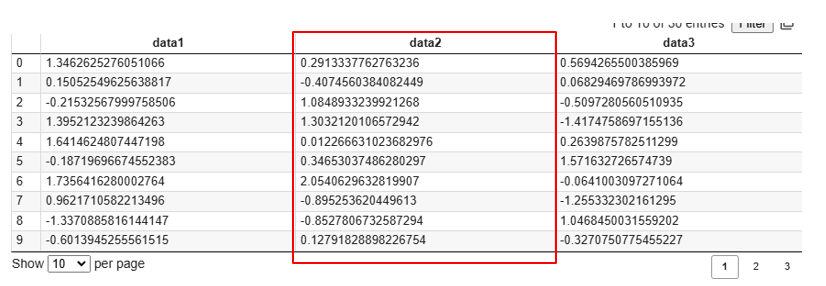
# 行インデックスが4以上7未満、列インデックスが1以上4未満の範囲を取得
print(data[4:7,1:4])実行結果
[[ 1.64146248 0.01226663 0.26398758]
[-0.18719697 0.34653037 1.57163273]
[ 1.73564163 2.05406296 -0.06410031]]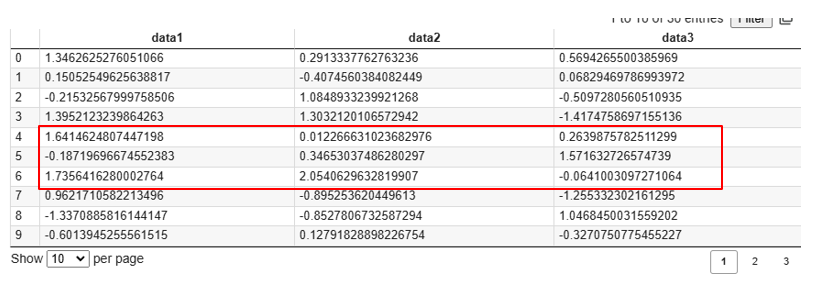
また、[]の中に条件式を書くことで、指定した条件に基づくデータを取得することができます
前述したdata.csvデータを使って要素を取り出したサンプルプログラムを以下に示します
# 列インデックス2の値が1.5以上のデータを抽出
print(data[data[:,2]>=1.5])
実行結果
[[ 6. 1.73564163 2.05406296 -0.06410031]
[12. 2.23373661 1.7228992 -0.16046507]
[17. 0.31118053 1.9395611 -0.75925323]
[21. 1.49625666 2.35893798 0.68124251]
[26. 0.52691362 3.26214759 0.19713629]]統計量を求める
平均値、最大値、最小値といった統計量は、mean、max、min関数を利用して求めることができます
numpy.mean(配列)
numpy.max(配列)
numpy.min(配列)
また、軸番号を指定することで、特定の次元に対してそれぞれ求めることができます
numpy.mean(配列,axis=軸番号)
numpy.max(配列,axis=軸番号)
numpy.min(配列,axis=軸番号)
前述したdata.csvデータを使って要素を取り出すサンプルプログラムを以下に示します
# 列インデックスが1の平均の計算
mean = np.mean(data[:,1])
print(mean)
# 列インデックスが3の最大値の取得
max = np.max(data[:,3])
print(max)
# 列インデックスが3の最小値の取得
min = np.min(data[:,3])
print(min)
実行結果
0.19731645140507142
2.664358294253872
-1.4451536218143848# 各列ごとの平均値
mean = np.mean(data,axis=0)
print(mean)
# 各列ごとの最大値
max = np.max(data,axis=0)
print(max)
# 各列ごとの最小値
min = np.min(data,axis=0)
print(min)実行結果
[14.5 0.19731645 0.24786983 0.28484253]
[29. 2.23373661 3.26214759 2.66435829]
[ 0. -1.65790249 -2.32578498 -1.44515362]axis=0と指定することで各列の平均値、最大値、最小値を取得しています
【演習問題】
以下の手順に従って、演習を行いましょう
- 以下のデータを持つCSVファイルを作成し、ファイルを読み込みNumpyの配列を生成する
※ある教室での、国語、算数、社会の得点を表すデータ
国語,算数,社会
46,49,57
33,29,76
15,11,52
17,38,39
40,74,63
71,90,98
84,74,100
66,77,100
72,30,54
33,35,46
82,90,12
62,6,87
14,76,51
69,16,89
95,68,1
37,14,71
3,98,11
96,97,94
45,23,38
52,44,65
88,68,22
実行結果
[[ 46. 49. 57.]
[ 33. 29. 76.]
[ 15. 11. 52.]
[ 17. 38. 39.]
[ 40. 74. 63.]
[ 71. 90. 98.]
[ 84. 74. 100.]
[ 66. 77. 100.]
[ 72. 30. 54.]
[ 33. 35. 46.]
[ 82. 90. 12.]
[ 62. 6. 87.]
[ 14. 76. 51.]
[ 69. 16. 89.]
[ 95. 68. 1.]
[ 37. 14. 71.]
[ 3. 98. 11.]
[ 96. 97. 94.]
[ 45. 23. 38.]
[ 52. 44. 65.]
[ 88. 68. 22.]]
<class 'numpy.ndarray'>- 1で取得した配列から、shape,ndim,dtype,sizeを取得し表示する
実行結果
(21, 3)
float64
2
63- 1で取得したNumpyの配列の特定の要素を取得する
・国語の列の値を取得する
・算数列の値が60以上の行を取得する
実行結果
[46. 33. 15. 17. 40. 71. 84. 66. 72. 33. 82. 62. 14. 69. 95. 37. 3. 96.
45. 52. 88.]
[[ 40. 74. 63.]
[ 71. 90. 98.]
[ 84. 74. 100.]
[ 66. 77. 100.]
[ 82. 90. 12.]
[ 14. 76. 51.]
[ 95. 68. 1.]
[ 3. 98. 11.]
[ 96. 97. 94.]
[ 88. 68. 22.]]- 1で取得したNumpyの配列の統計量を求める
・各項目の平均値、最小値、最大値を取得する(axis=0とする)
実行結果
[53.33333333 52.71428571 58.38095238]
[ 96. 98. 100.]
[3. 6. 1.]

{kind=link}
コメント