
1日目
「1日目:関数について」演習問題
【問1】
可変長の数値の引数を受け取り、その合計を返す関数を作成してみましょう
関数は以下のような関数を作成します
def sum_number(*args):
処理【問2】
可変数の位置引数とキーワード引数の両方を受け取り、それらをすべて出力する関数を作成してみましょう
関数は以下のような関数を作成します
def print_all_arguments(*args, **kwargs):
処理実行結果(例)
位置引数:
1
2
3
キーワード引数:
name: Bob
age: 25
country: Canada
「1日目:関数について」解答例
【問1】
def sum_number(*args):
s = 0
for i in args:
s += i
return s
total=sum_number(1,2,3,4,5)
print(total)
tl = [1,2,3,4,5,6,7,8,9,10]
print(sum_number(*tl))
実行結果
15
55
【問2】
def print_all_arguments(*args, **kwargs):
"""
可変数の位置引数とキーワード引数の両方を受け取り、それらをすべて出力する関数。
"""
print("位置引数:")
for arg in args:
print(arg)
print("キーワード引数:")
for key, value in kwargs.items():
print(f"{key}: {value}")
# 位置引数とキーワード引数の両方を渡して関数を呼び出します
print_all_arguments(1, 2, 3, name="Bob", age=25, country="Canada")
2日目
「2日目:Pythonでのクラスについて」演習問題
【問1】
Circleクラスを作成し円周、面積を計算するメソッドを実装し、(1)、(2)を作成してみましょう
Circleクラス:
半径
面積を計算するメソッド
円周を計算するメソッド
※円周率は3.14とする
(1) Circleクラスからインスタンスを作成する
(2) 半径から円の面積、円周を計算し表示する
実行結果
半径を入力してください:4.5
円の面積:63.585
円周の長さ:28.26「2日目:Pythonでのクラスについて」解答例
【問1】
class Circle:
def __init__(self, radius):
self.radius = radius
def area(self):
return 3.14 * self.radius ** 2
def round(self):
return 3.14 * self.radius * 2
radius = float(input("半径を入力してください:"))
c1 = Circle(radius)
print("円の面積:" + str(c1.area()))
print("円周の長さ:" + str(c1.round()))
「2日目:クラスの継承と派生」演習問題
【問1】
次の要件を満たすプログラムを作成してみましょう
Personクラス:
名前(文字列)
性別(文字):’m’→男性、’f’→女性を表す
年齢(整数)
表示するためのメソッド(Introduction)を用意:名前、性別、年齢を表示
Patientクラス:(Personクラスからの派生クラスとして作成する)
身長(cm)
体重(kg)
表示するためのメソッド(Introduction)を用意:名前、性別、年齢、身長、体重を表示
適正体重(BMI)より大きいか小さいかを表示するメソッドを作成する
※ 適正体重(BMI)=体重(kg) ÷ (身長(m)× 身長(m))
(1)Patientクラスからインスタンスを作成し指定した名前、性別、年齢、身長、体重を表示する
(2)適正体重(BMI)が25より大きければ「肥満です」、小さければ「肥満ではありません」と表示する
実行結果
私の名前はTaroです。
年齢は21です。
性別は男性です。
身長は175.5cmです。
体重は65.7kgです。
肥満ではありません。
「2日目:クラスの継承と派生」解答例
【問1】
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def getGender(self):
if self.gender == 'm':
return '男性'
elif self.gender == 'f':
return '女性'
else:
return 'その他'
def introduction(self):
print("私の名前は" + self.name + "です。")
print("年齢は" + str(self.age) + "です。")
print("性別は" + self.getGender() + "です。")
class Patient(Person):
def __init__(self,name,age,gender,height,weight):
super().__init__(name,age,gender)
self.height = height
self.weight = weight
def introduction(self):
super().introduction()
print("身長は" + str(self.height) + "cmです。")
print("体重は" + str(self.weight) + "kgです。")
def isOverWeight(self):
bmi = self.weight / (self.height / 100) ** 2
if bmi >= 25:
return True
else:
return False
p = Patient("Taro",21,'m',175.5,65.7)
p.introduction()
if p.isOverWeight() == True:
print("肥満です。")
else:
print("肥満ではありません。")
3日目
「3日目:例外を捉える」演習問題
【問1】
次のプログラムを実行すると下のような出力結果が得られます
このプログラムをtry-except文を使い書き換えてみましょう
def add(x, y):
return x + y
mylist = [1,2,3,4,5]
s1 = add(mylist[0],mylist[5])
s2 = add(mylist[0],mylist[4])
print(s1)
print(s2)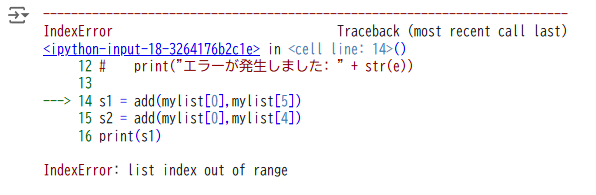
【問2】
標準入力から任意の整数を入力し9が入力されたら終了するプログラムをtry-exceptを使用して作成してください
実行結果
任意の整数を入力してください(9:終了):1
1
任意の整数を入力してください(9:終了):d
整数を入力してくださいinvalid literal for int() with base 10: 'd'
任意の整数を入力してください(9:終了):6
6
任意の整数を入力してください(9:終了):9
終了します
「3日目:例外を捉える」解答例
【問1】
def add(x, y):
return x + y
mylist = [1,2,3,4,5]
try:
s1 = add(mylist[0],mylist[5])
s2 = add(mylist[0],mylist[4])
print(s1)
print(s2)
except Exception as e:
print("エラーが発生しました: " + str(e))
実行結果
エラーが発生しました: list index out of range【問2】
while True:
try:
x = int(input("任意の整数を入力してください(9:終了):"))
if x == 9:
print("終了します")
break
print(x)
except ValueError as e:
print("整数を入力してください"+str(e))
4日目
「4日目:テキストファイルの読み書き」演習問題
【問1】
リストに含まれる文字列を1行ずつファイルに出力してみましょう
リストは次の通り定義します
s1 = [“Tokyo”,”Osaka”,”Nagoya”]
出力結果(ファイルの中身のダンプ)
Tokyo
Osaka
Nagoya【問2】
【問1】で出力したファイルから1行ずつよみこみ、リストを生成し表示してみましょう
実行結果
['Tokyo', 'Osaka', 'Nagoya']「4日目:テキストファイルの読み書き」解答例
【問1】
s1 = ["Tokyo","Osaka","Nagoya"]
with open("./test2.txt","w",encoding="utf-8") as fo:
for s in s1:
fo.write(s+"\n")
【問2】
l = []
with open("./test2.txt","r",encoding="utf-8") as fo:
for line in fo:
l.append(line.strip())
print(l)「4日目:CSVファイルの読み書き」演習問題
【問1】
以下のような出力ファイルになるようにCSVファイルへ出力してみましょう
実行結果(出力ファイルのダンプ)
coffee,350,2
tea,300,4
water,0,5
milk,200,1
juice,150,2【問2】
【問1】で作成したファイルを読み込み、各行をリストに追加し、作成できたリストを出力するプログラムを作成してみましょう
実行結果
[['coffee', '350', '2'], ['tea', '300', '4'], ['water', '0', '5'], ['milk', '200', '1'], ['juice', '150', '2']]「4日目:CSVファイルの読み書き」解答例
【問1】
import csv
header = ["menu","単価","数量"]
menulist = [
("coffee",350,2),
("tea",300,4),
("water",0,5),
("milk",200,1),
("juice",150,2),
]
with open("./test4.csv","w",encoding="utf-8",newline='') as fo:
csvwriter = csv.writer(fo)
csvwriter.writerows(menulist)
【問2】
import csv
l = []
with open("./test4.csv","r",encoding="utf-8",newline='') as fo:
csvreader = csv.reader(fo)
for row in csvreader :
l.append(row)
print(l)
「4日目:JSONファイルの読み書き」演習問題
【問1】
menu、価格、数量をキーに持つ辞書をまとめリストに格納した上で、menulist.jsonというJSONファイルを出力してみましょう
出力結果
[
{
"menu": "coffee",
"単価": 350,
"数量": 2
},
{
"menu": "tea",
"単価": 300,
"数量": 4
},
{
"menu": "water",
"単価": 0,
"数量": 5
},
{
"menu": "milk",
"単価": 200,
"数量": 1
},
{
"menu": "juice",
"単価": 150,
"数量": 2
}
]
【問2】
【問1】で作成したmenulist.jsonファイルを読み込み、以下のように出力してみましょう
実行結果
coffee:単価350円
販売数量:2 小計:700円
***************
tea:単価300円
販売数量:4 小計:1200円
***************
water:単価0円
販売数量:5 小計:0円
***************
milk:単価200円
販売数量:1 小計:200円
***************
juice:単価150円
販売数量:2 小計:300円
***************
「4日目:JSONファイルの読み書き」解答例
【問1】
import json
menulist = [
{"menu":"coffee","単価":350,"数量":2},
{"menu":"tea","単価":300,"数量":4},
{"menu":"water","単価":0,"数量":5},
{"menu":"milk","単価":200,"数量":1},
{"menu":"juice","単価":150,"数量":2}
]
with open("./menulist.json","w",encoding="utf-8") as fo:
json.dump(menulist,fo,ensure_ascii=False,indent=2)
【問2】
import json
l = []
with open("./menulist.json","r",encoding="utf-8") as fo:
l = json.load(fo)
for item in l:
print(item['menu']+":"+"単価" + str(item['単価']) + "円")
print("販売数量:"+ str(item['数量']),end=" ")
print("小計:"+str(item['単価']*item['数量'])+"円")
print("***"*5)
5日目
「5日目:Numpy配列」演習問題
以下の手順に従って、演習を行いましょう
【問1】
以下のデータを持つCSVファイルを作成し、ファイルを読み込み、Numpyの配列を生成してみましょう
※ある教室での、国語、算数、社会の得点を表すデータ
国語,算数,社会
46,49,57
33,29,76
15,11,52
17,38,39
40,74,63
71,90,98
84,74,100
66,77,100
72,30,54
33,35,46
82,90,12
62,6,87
14,76,51
69,16,89
95,68,1
37,14,71
3,98,11
96,97,94
45,23,38
52,44,65
88,68,22実行結果
[[ 46. 49. 57.]
[ 33. 29. 76.]
[ 15. 11. 52.]
[ 17. 38. 39.]
[ 40. 74. 63.]
[ 71. 90. 98.]
[ 84. 74. 100.]
[ 66. 77. 100.]
[ 72. 30. 54.]
[ 33. 35. 46.]
[ 82. 90. 12.]
[ 62. 6. 87.]
[ 14. 76. 51.]
[ 69. 16. 89.]
[ 95. 68. 1.]
[ 37. 14. 71.]
[ 3. 98. 11.]
[ 96. 97. 94.]
[ 45. 23. 38.]
[ 52. 44. 65.]
[ 88. 68. 22.]]
<class 'numpy.ndarray'>
【問2】
【問1】で取得した配列から、shape,ndim,dtype,sizeを取得し表示してみましょう
実行結果
(21, 3)
float64
2
63
【問3】
【問1】で取得したNumpyの配列の特定の要素を取得してみましょう
・国語の列の値を取得する
・算数列の値が60以上の行を取得する
実行結果
[46. 33. 15. 17. 40. 71. 84. 66. 72. 33. 82. 62. 14. 69. 95. 37. 3. 96.45. 52. 88.]
[[ 40. 74. 63.]
[ 71. 90. 98.]
[ 84. 74. 100.]
[ 66. 77. 100.]
[ 82. 90. 12.]
[ 14. 76. 51.]
[ 95. 68. 1.]
[ 3. 98. 11.]
[ 96. 97. 94.]
[ 88. 68. 22.]]【問4】
【問1】で取得したNumpyの配列の統計量を求めてみましょう
・各項目の平均値、最小値、最大値を取得する(axis=0とする)
実行結果
[53.33333333 52.71428571 58.38095238]
[ 96. 98. 100.]
[3. 6. 1.]
「5日目:Numpy配列」解答例
【問1】
# CSVファイルの生成
import csv
l = [
(46,49,57),
(33,29,76),
(15,11,52),
(17,38,39),
(40,74,63),
(71,90,98),
(84,74,100),
(66,77,100),
(72,30,54),
(33,35,46),
(82,90,12),
(62,6,87),
(14,76,51),
(69,16,89),
(95,68,1),
(37,14,71),
(3,98,11),
(96,97,94),
(45,23,38),
(52,44,65),
(88,68,22),
]
with open("kadai.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["国語","算数","社会"])
writer.writerows(l)
import numpy as np
data = np.loadtxt('./kadai.csv', delimiter=',',skiprows=1)
print(data)
【問2】
print(type(data))
print(data.shape)
print(data.dtype)
print(data.ndim)
print(data.size)【問3】
print(data[:,0])
print(data[ data[:,1]>=60])【問4】
mean = np.mean(data,axis=0)
print(mean)
max = np.max(data,axis=0)
print(max)
min = np.min(data,axis=0)
print(min)
6日目
「6日目:DataFrameについて」演習問題
以下の手順に従って、演習を行いましょう
・導入
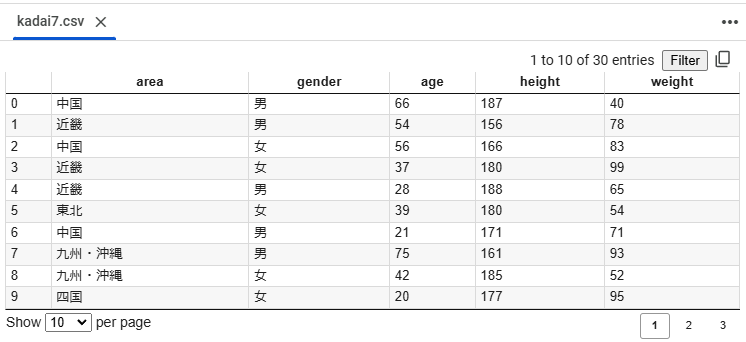
次のプログラムを実行しkadai7.csvというファイルを作成します
データは地域(area)、性別(gender)、年齢(age)、身長(height)、体重(weight)を持っているデータです
import pandas as pd
import numpy as np
area_list = ["北海道", "東北", "関東", "中部", "近畿", "中国", "四国", "九州・沖縄"]
gender_list = ["男", "女"]
df = pd.DataFrame({'area': np.random.choice(area_list, 30),
'gender': np.random.choice(gender_list, 30),
'age': np.random.randint(18,80,30),
'height': np.random.randint(150,200,30),
'weight': np.random.randint(40,100,30)
})
df.head()
df.to_csv('kadai7.csv')
【問1】
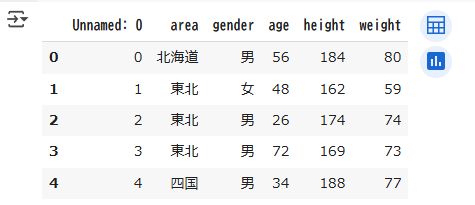
導入で作成したkadai7.csvを読み込み、先頭から5行分表示してみましょう
【問2】
導入で作成したkadai7.csvを読み込み、年齢(age)の最大値と最小値を取得してみましょう
【問3】
導入で作成したkadai7.csvを読み込み、体重(weight)が一番多いインデックスと地域名を取得してみましょう
【問4】
導入で作成したkadai7.csvを読み込み、身長(height)の平均値を計算してみましょう
「6日目:DataFrameについて」解答例
・導入
kadai7.csv
【問1】
import pandas as pd
df = pd.read_csv("kadai7.csv",encoding="utf-8")
df.head(5)
【問2】
print(df['age'].min())
print(df['age'].max())【問3】
index = df['weight'].idxmax()
print(index)
print(df.loc[index,'area'])【問4】
print(df['height'].mean())7日目
「7日目:棒グラフを表示」演習問題
【問1】
枠線の色や棒の太さ、棒の位置、横軸のラベルなどの引数を渡して、それぞれ変更してみましょう
「7日目:円グラフを表示」演習問題
【問1】
その他の引数も渡して、それぞれ変更してみましょう
「7日目:凡例の表示」演習問題
以下の手順に従って、演習を行いましょう
【問1】
Python 応用編 6回目の演習問題で生成したkadai7.csvを読み込みます
生成方法はPython 応用編 6日目の演習問題を参照してください
【問2】
areaごとのageの平均値を計算し、ageの円グラフで表示してみましょう
【問3】
areaごとの身長の平均値を計算し、棒グラフで表示してみましょう
「7日目:凡例の表示」解答例
【問1】
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import japanize_matplotlib
df = pd.read_csv("kadai7.csv")
group_list = df.groupby('area')
# height, weight, ageの平均を計算
mean_values = group_list[['height', 'weight', 'age']].mean()
print(mean_values)
print(mean_values.index)
print(mean_values.columns)
実行結果
height weight age
area
中国 176.000000 93.000000 68.666667
中部 166.000000 58.500000 39.250000
九州・沖縄 193.000000 62.000000 65.000000
北海道 183.666667 78.166667 47.666667
四国 167.250000 67.500000 36.250000
東北 170.000000 60.800000 49.600000
近畿 186.000000 69.666667 60.333333
関東 174.250000 77.000000 28.000000
Index(['中国', '中部', '九州・沖縄', '北海道', '四国', '東北', '近畿', '関東'], dtype='object', name='area')
Index(['height', 'weight', 'age'], dtype='object')
【問2】
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import japanize_matplotlib
df = pd.read_csv("kadai7.csv")
group_list = df.groupby('area')
# height, weight, ageの平均を計算
mean_values = group_list[['height', 'weight', 'age']].mean()
age_list = mean_values['age']
print(age_list)
plt.pie(age_list,labels=mean_values.index,autopct='%.1f%%')
plt.title('地域別平均年齢比')
plt.show()
【問3】
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import japanize_matplotlib
df = pd.read_csv("kadai7.csv")
group_list = df.groupby('area')
# height, weight, ageの平均を計算
mean_values = group_list[['height', 'weight', 'age']].mean()
height_list = mean_values['height']
print(height_list)
plt.bar(height_list.index,height_list)
plt.title('地域別平均身長')
plt.show()


{kind=link}
コメント